How It Works
The Protocol
Fluence protocol forms the network of compute resources and defines the cloudless stack to execute computations.
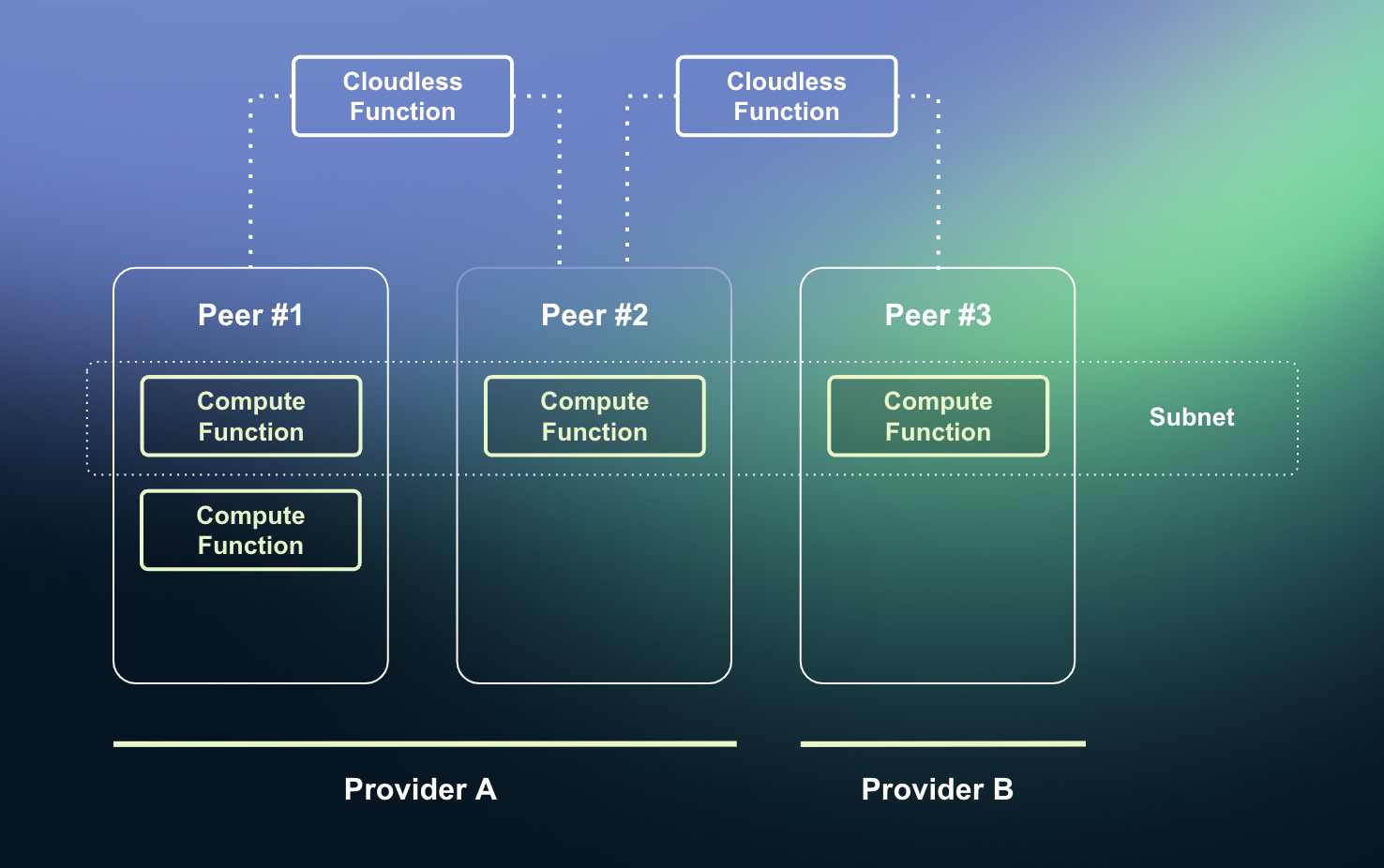 Fluence network overview
Fluence network overview
Cloudless Functions, Aqua
The Fluence network runs entirely on the Aqua protocol which provides secure distributed execution without centralized coordination. The Aqua name is also used for a domain specific scripting language that is compiled down to pi-calculus operations and allows the expression of deadlock-free distributed algorithms. The Aqua protocol is deploy-free: Aqua scripts are packaged into data packets and are executed as they go over the network as programmed by scripts themselves. Additionally, Aqua guarantees cryptographic security on script execution: all requests and their step by step execution are signed by participating peers, making executed scripts auditable and verifiable.
Code created with Aqua we call Cloudless Functions, because it runs cross-cloud, cross-server, and cross-geographies. Cloudless Functions power both customer applications and the Fluence protocol itself. Service discovery, routing, load balancing, subnets initiation and operation, scaling, and fault tolerance algorithms are all run over Aqua and expressed as Cloudless Functions.
Compute Functions, Marine
While Aqua operates the topology and flow of the execution over servers and clouds, for running computation on nodes, Fluence uses Marine, a WebAssembly runtime allowing multi-module execution, incorporating interface-types and WASI for effector access.
Marine powers Compute Functions, that are executed within single machine similarly to serverless cloud functions. Marine supports Rust and C++ as source languages, but more languages are coming with the development of the WebAssembly standard.
Subnets
All Compute Functions in the network are being deployed with replication to ensure fault tolerance: in the event a node becomes unavailable due to a hardware fault or network disruption. Replicated deployments are called Subnets. Subnet operation is fully customizable by developers via Cloudless Functions, so developers may enable failovers, load balancing, consensus, or any other custom algorithms.
Subnets enable creation of highly available data storage on Fluence. Think about hot cache or data indexing, while storing large amounts of data is outsourced to external storage networks, whether centralized (S3) or decentralized (Filecoin/Arweave).
Proofs of Compute
The Fluence protocol enforces generation of cryptographic proofs for all execution in the network. Providers generate proofs for their computation and customers pay only for the work accompanied by proofs that the work was validated and correct.
Aqua Security
When peers operate in Fluence, they constantly serve incoming Cloudless Function calls that in its turn require relaying the function further or running a Compute Function on that peer. For every incoming Cloudless Function, the peer validates the execution trace of previous involved peers, ensuring that the execution of this flow happens correctly. Cloudless Functions executed by wrong peers or disturbed topology are discarded.
If a Cloudless Function demands the peer to run a Compute Function, the peer does the job, expands the execution trace, and forwards the request further as requested. This way, the protocol ensures the correct operation and produces audit trails for all executions.
Proof of Processing
The protocol enforces probabilistic validation on-chain for Aqua executions. Because all computations are wrapped into Aqua, it means that everything that is executed on the platform probabilisticly gets verified on-chain. Providers have to submit required executions in order to earn rewards or will be slashed.
Proof of Execution
A cryptographic proof for particular code execution on Fluence. Every function execution is accompanied with this proof produced by Fluence’s Marine WebAssembly runtime. These proofs are validated by nodes participating in follow-on execution and included in Proof of Processing.
The Marketplace
On-chain marketplace matches compute providers with customers who pay for using the compute resources offered by providers. The marketplace is completely permissionless, so any providers may participate and publish their available capacity.
The marketplace is hosted on Fluence's own chain powered by IPC, validated by Fluence Compute Providers and anchored to Filecoin L1. The own chain enables cheap and fast transactions to enable renting compute resources at any scale: from tiny loads to massive scale.
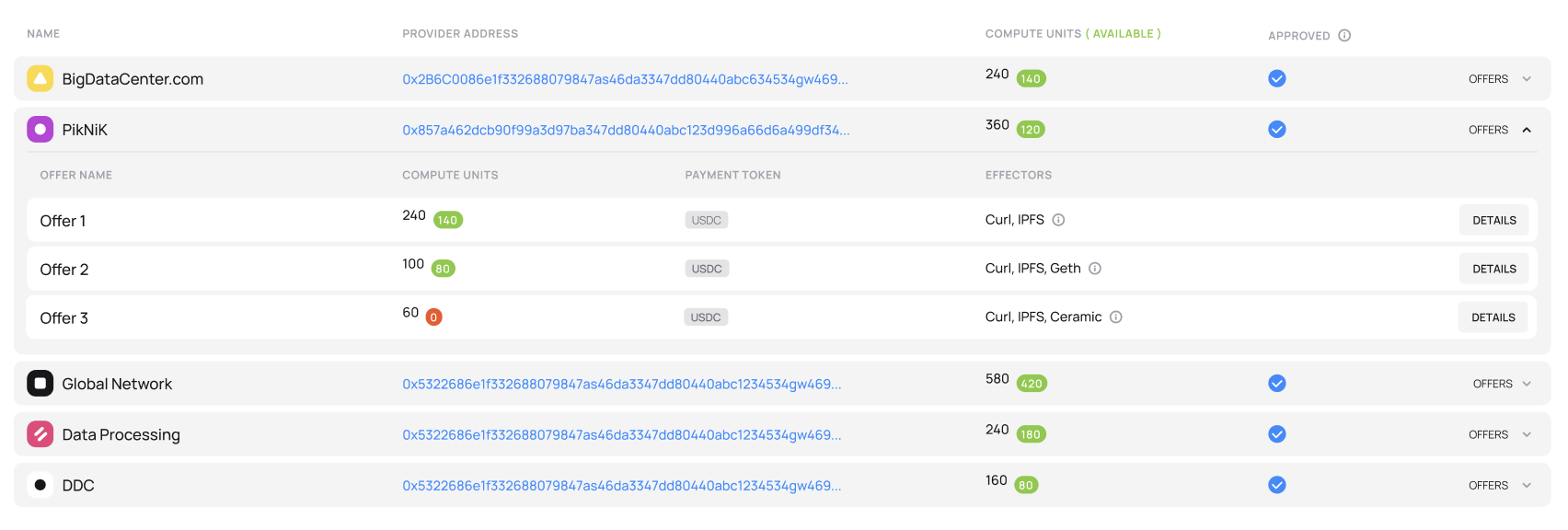 Compute providers on the Fluence marketplace
Compute providers on the Fluence marketplace
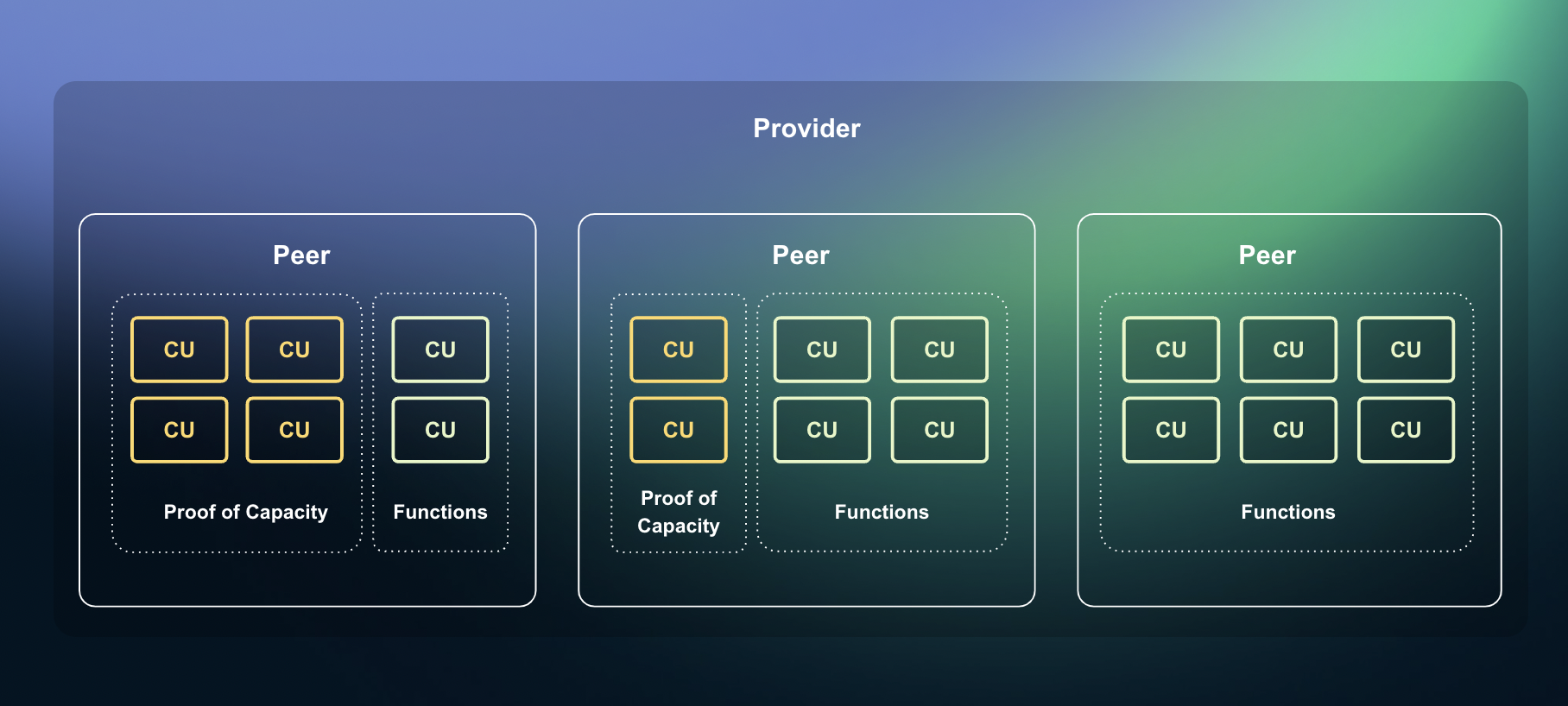 Compute provider resources
Compute provider resources
Proof of Capacity
Fluence ensures that resources advertized by providers exist and available by enforcing a cryptographic proof called Proof of Capacity. Providers apply their hardware resources to constantly generate Proofs of Capacity to confirm that these resources are ready to serve customers. Protocol rewards such resources with Fluence token proportionally to the allocated power.
Whenever customers need computing power from chosen providers, these resources are switched from generating proofs to serving customers' application.
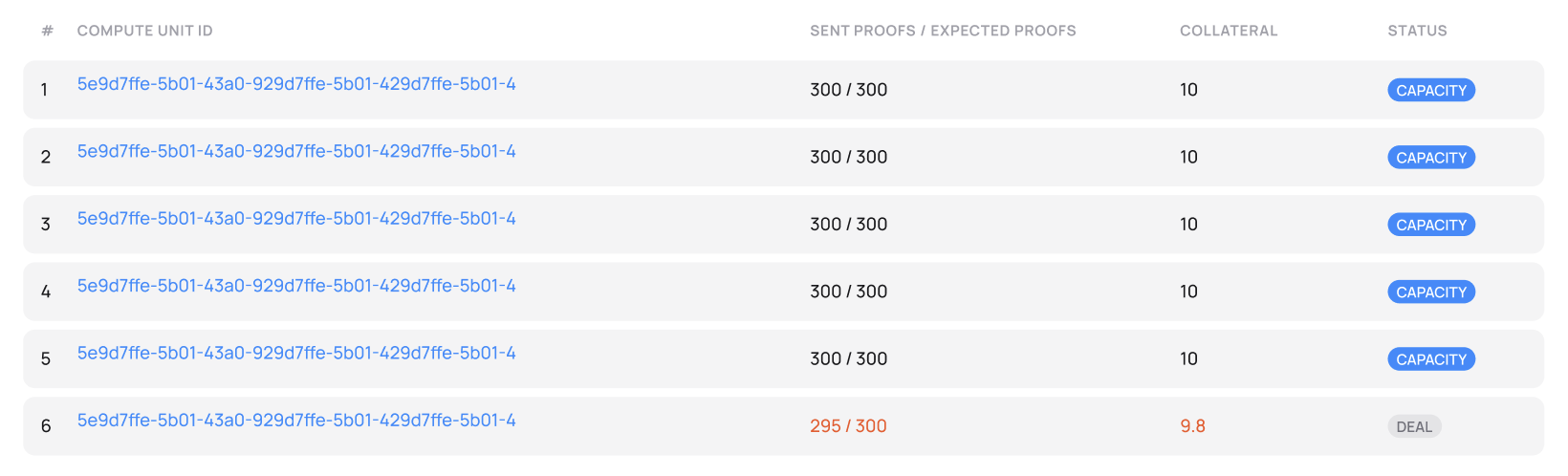 Compute units submitting Proofs of Capacity
Compute units submitting Proofs of Capacity
Resource Pricing
Customers may select providers by price advertised and other parameters, or alternatively publish work and required max price to be picked up by any provider.
Under-the-hood, for every application deployment, a Deal is being created on-chain between a customer and list of providers. Deals record financial detail (prices, pre-payment, and required collaterals from providers), technical requirements related to required services (access to certain data, binaries or web API), and a link to code installations in the network.
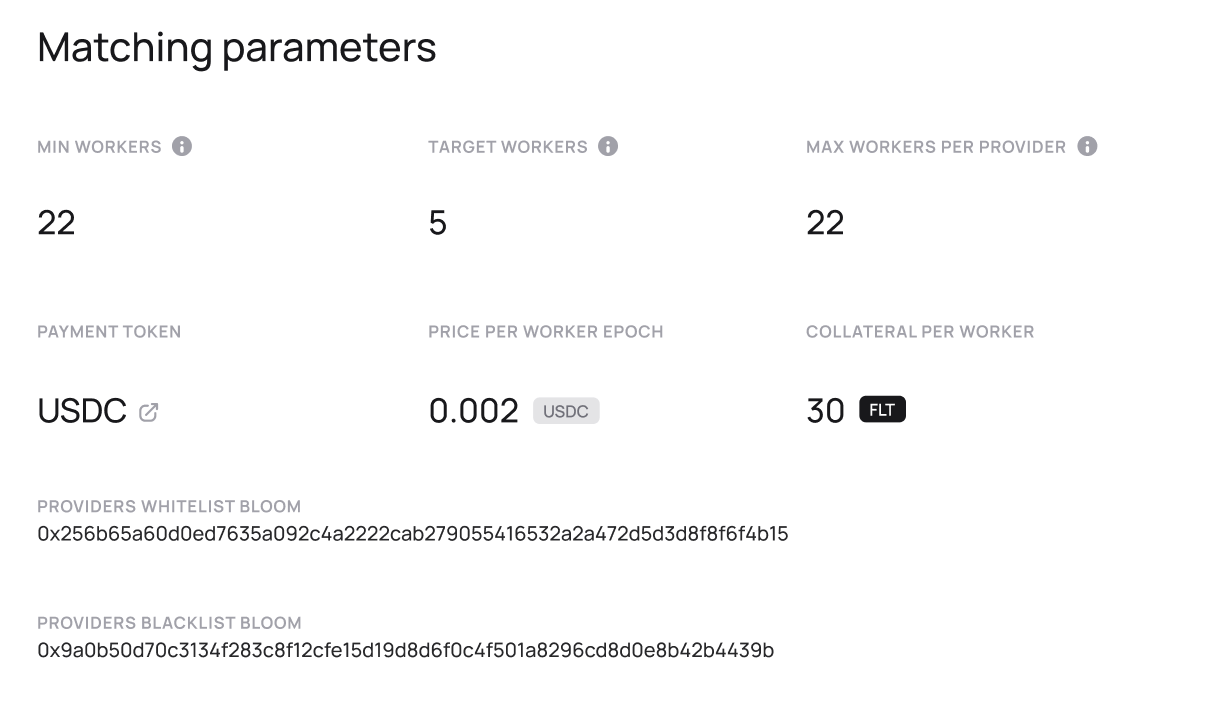 Matching criteria for selecting providers
Matching criteria for selecting providers
Billing model
Initially, the billing model is pre-paid, based on time of resource rental and accounted in epochs. Minimal resource rental is a single Compute Unit for 2 epochs, where one epoch is defined as 1 day, and Compute Unit is 1 core, 4GB memory, 5GB virtual disk space. Pre-payment for minimal period is required from the customer so providers are ensured of getting paid for work.
The request-based billing model, and Elastic Compute Units will be introduced in next stages of the project.
The Network
The Fluence network can be thought of as a global set of interconnected nodes, each of which runs AquaVM and Marine, capable of receiving commands for deploying and executing code locally and collaborating with other nodes as specified by the received Cloudless Function. Most of these nodes are constantly involved in economic activity: they monitor and enter into Deals, form new Subnets or adjust participation in Subnets, install applications as specified by Deals, coordinate execution and serve incoming requests. They also produce proofs of the execution and submit them as specified by proof algorithms to receive rewards.